Computational data retrieval
After this chapter, the students can retrieve online data using curl and git, and convert simple json-formatted data to tab-format. They can utilise zip, gzip and tar commands to pack and unpack either single or multiple files.
Previously, we analysed the temperature data from the Finnish Meteorological Institute (FMI). The FMI provides a web site for the download of the observations at https://en.ilmatieteenlaitos.fi/download-observations. Although this interface allows a fairly easy way to obtain very large quantities of data, it still requires manual work. The FMI has an API (application programming interface) to access the data computationally but I couldn’t find an easy way to access the data with bash tools.
The bash tools tend to work well with REST (REpresentational State Transfer) APIs and my Google search with “open temperature data rest” found Open-Meteo as one example of such. We’ll test that with the bash tools.
Http access with curl
The command curl can read a URL of a web address and download the contents. The data analysed on this course is in GitHub and the measurements for the Malmi airport are in the raw format here. We could download the data through web browser but can do it easier with the bash commands:
> mkdir ~/IntSciCom/Helsinki/openmeteo
> cd ~/IntSciCom/Helsinki/openmeteo
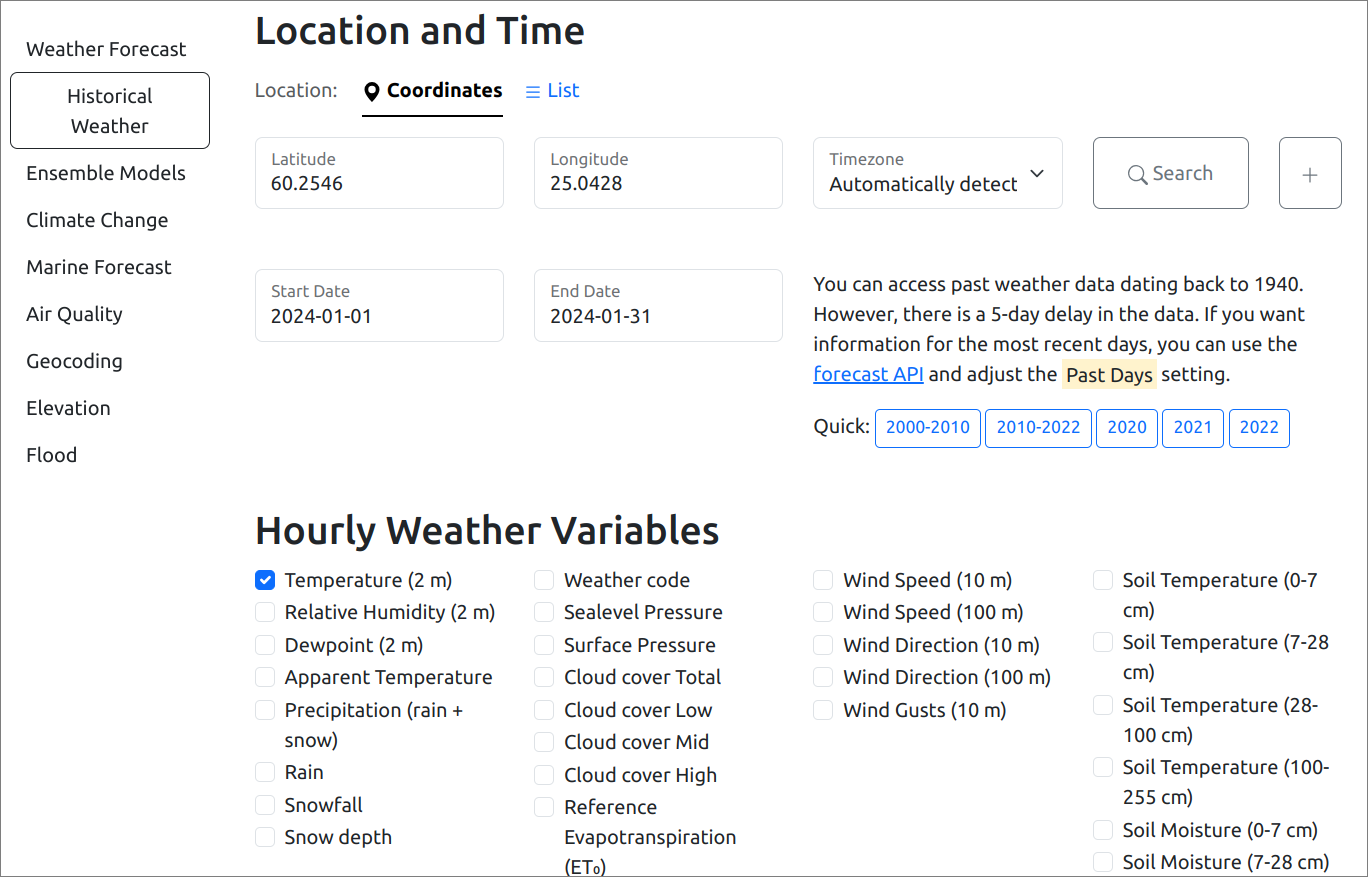
> curl https://raw.githubusercontent.com/ariloytynoja/IntSciCom/main/Helsinki/Helsinki_Malmi_lentokentt%C3%A4_1.1.2024-31.1.2024.csv -o Helsinki_Malmi_1.1.2024-31.1.2024.csvThe Open-Meteo REST API is documented at https://open-meteo.com/en/docs. With the search box, we can find the Helsinki Malmi airport and its exact coordinates, 60.2546 and 25.0428. We can set the Timezone to “Automatically detect time zone” and set date interval as 2024-01-01 and 2024-01-31. From the “Hourly Weather Variables”, we click “Temperature (2m)”. These settings give this page, looking like this:
The important part is lower at the page:
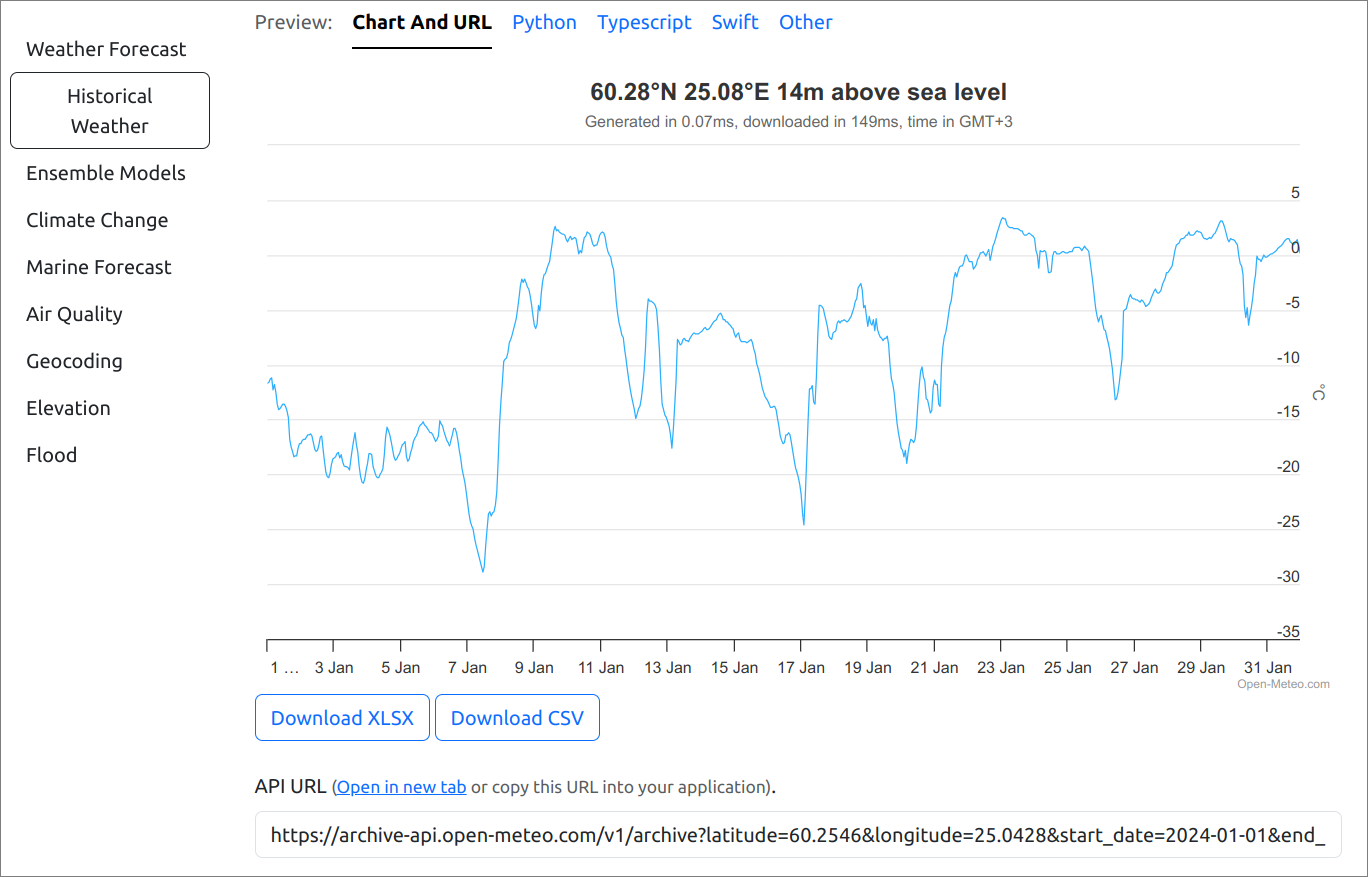
At the bottom, we see the text “API URL (Open in new tab or copy this URL into your application).” One can open the URL in a new tab and see the output. It looks like dates and temperatures but the format is odd. The output is in JSON (Java Script Object Notation) format supported by many programming languages. We’ll return to that soon.
The important part is the URL. It starts with “https://archive-api.open-meteo.com/v1/archive?” and that is fixed for all queries. After the question mark comes parameter=value pairs, separated by ampersands (&). The parameters are these:
latitude=60.254longitude=25.0428hourly=temperature_2mtimezone=autostart_date=2024-01-01end_date=2024-01-31
and their meaning is fairly obvious. Crucially, we could edit these parameters manually (or programmatically) if we would like to get the measurement e.g. for February, 2024. The order of the parameters doesn’t matter.
We can download the output in our terminal using the curl command with the URL generated at the Open-Meteo web site:
> curl "https://archive-api.open-meteo.com/v1/archive?latitude=60.2546&longitude=25.0428&hourly=temperature_2m&timezone=auto&start_date=2024-01-01&end_date=2024-01-31" > Malmi.jsonOne can have a look inside the json-file with less:
> less Malmi.json(One can quit less with the key q.)
The structure of the json-file becomes clearer with the program jq, a command-line JSON processor:
> jq -r < Malmi.json | head -20{
"latitude": 60.281193,
"longitude": 25.081966,
"generationtime_ms": 0.05900859832763672,
"utc_offset_seconds": 10800,
"timezone": "Europe/Helsinki",
"timezone_abbreviation": "EEST",
"elevation": 14,
"hourly_units": {
"time": "iso8601",
"temperature_2m": "°C"
},
"hourly": {
"time": [
"2024-01-01T00:00",
"2024-01-01T01:00",
"2024-01-01T02:00",
"2024-01-01T03:00",
"2024-01-01T04:00",
"2024-01-01T05:00",The parameters are clearly correct and the intended data are there, but everything is in a very difficult format. We can extract and convert the two data fields into tsv-format with a more complex jq command:
> jq -r '[.hourly.time,.hourly.temperature_2m] | transpose[] | @tsv' Malmi.json > Malmi_OpM.tsv
> head -3 Malmi_OpM.tsv2024-01-01T00:00 -11.7
2024-01-01T01:00 -11.6
2024-01-01T02:00 -11.3The data are now in tsv-format. The date field is different from the ones seen before, but its structure is pretty obvious.
jq
The details of jq are beyond this course, partly because I don’t know the tool at all and have never used it before. When building this exercise I realised that the json-formatted data must be converted to tsv-format and concluded that there must be a command-line program for this task. Google searches with “bash convert json tsv” led to jq and with some experimenting, I found a way to transpose the data within the jq command. It appears tha jq can do lots more and is probably highly useful for anyone working with json-formatted data. The program homepage is at https://jqlang.github.io/jq/ but the tutorial there is pretty limited. A Google search will find better ones.
The moral of the story is that there probably exists a tool or a combination of tools for pretty much every imaginable data manipulation problem. The challenge is to phrase the problem such that a Google search will find reasonable hits.
We can convert the data from the FMI to the same format using the conversion script that we developed earlier and some additional awk code:
> bash ../convert.sh Helsinki_Malmi_1.1.2024-31.1.2024.csv \
| awk '{printf "%d-%02d-%02dT%s\t%.1f\n",$2,$3,$4,$5,$6}' > Malmi_FMI.tsvA quick glance at the beginning of the files shows that the file formats are similar but the actual temperature values are surprisingly different:
> head -2 Malmi*tsv==> Malmi_FMI.tsv <==
2024-01-01T00:00 -16.7
2024-01-01T01:00 -16.6
==> Malmi_OpM.tsv <==
2024-01-01T00:00 -11.7
2024-01-01T01:00 -11.6We can join the files using the first column; the echo command adds a header line and the brackets ensure that the output of both commands is written to the output file:
> ( echo -e "Date FMI OpM" && join -j1 Malmi_FMI.tsv Malmi_OpM.tsv ) > Malmi.tsv
> head -3 Malmi.tsv | column -tDate FMI OpM
2024-01-01T00:00 -16.7 -11.7
2024-01-01T01:00 -16.6 -11.6One can visualise the differences between the two data sets using R or Python; I’m more familiar with R, but only Python is available on the course machine’s Jupyter interface. We can open a new Python notebook by clicking the blue plus-button in the top left corner and then selecting the Python 3 notebook:
On that notebook, one can make a very simple plot with these commands:
import pandas as pd
from matplotlib import pyplot as plt
dat = pd.read_csv('~/IntSciCom/Helsinki/openmeteo/Malmi.tsv',sep=" ")
dat.plot('Date', ['FMI','OpM']) One should copy them in the first cell (box) in the notebook and execute them with Ctrl+Enter or by clicking the triangle symbol in the top bar. That should produce a plot like this:
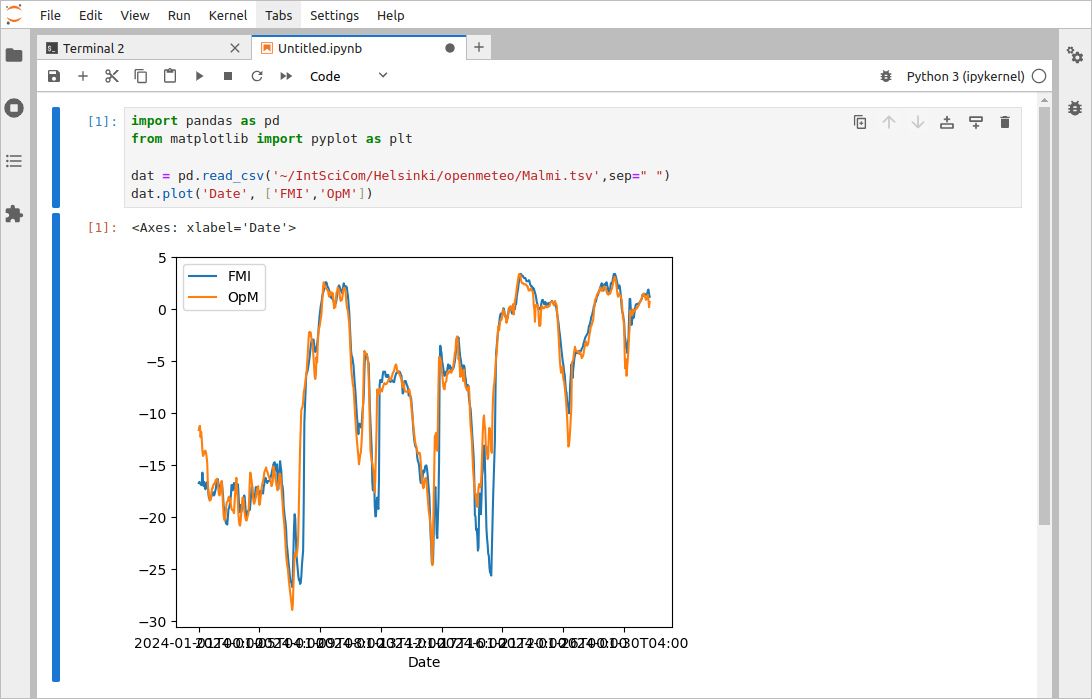
We can see that, in a few places, the temperature measurements loaded from the two sources differ, but overall, they follow the same pattern.
The differences between the two data sets are not the main point here and we do not study them further. Rather, the aim of the exercise was to computationally retrieve data from a service using the REST API; as many sites nowadays provide the data in the json-format, tools such as jq are becoming central and the rest of data harmonisation can be done with awk and sed.
Anyone having an own installation of Jupyter should seriously consider installing the R kernel. I run Jupyter on my laptop and a few other places and always install also the R kernel: I strongly prefer Jupyter R over RStudio! Unfortunately, the CSC computing clusters have a non-standard way of running the R environment and apparently they cannot make it run with Jupyter. On my own laptop, a simple R plot looks like this:
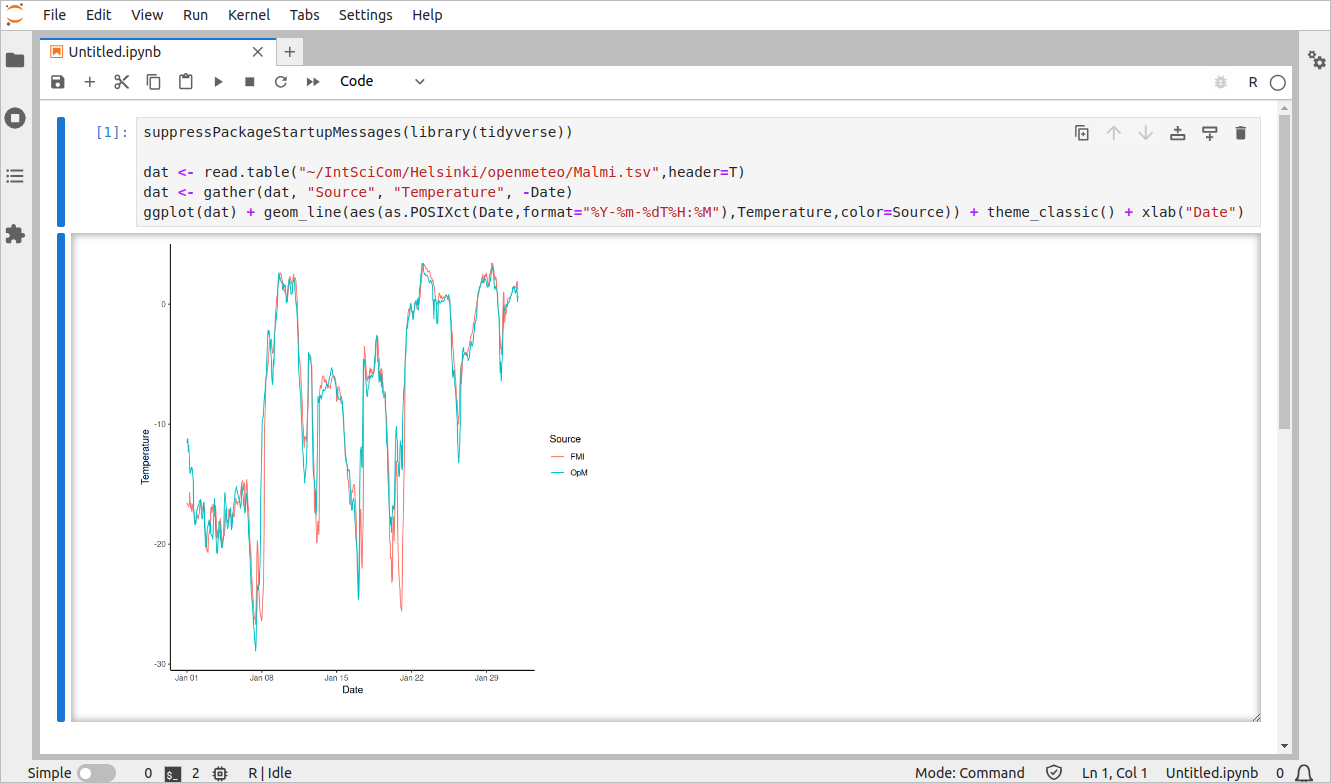
Data download with git
Primarily, the program git is a version control system, but it is also a means to share data or software. Here, we look at it in that role.
The data or software shared with git is hosted on a server such as GitHub or GitLab. For basic personal use, these services are free of charge. The University of Helsinki provides a local instance of GitLab at https://version.helsinki.fi/ that one can use with the UH username and credentials. GitHub and GitLab allow for controlling the data visibility and one can set the data to be private, visible for selected people or completely open. Here, we look at the use git for sharing open data and authentication is not required.
The dataset at https://version.helsinki.fi/aloytyno/helsinkiweather contains hourly mean temperature at the Malmi airfield for four Januaries in the 2020s. The data for three years have been named Malmi_[ABC].tsv and that for 2024 is found in Malmi_2024.tsv. The data repository can be cloned (creating a local copy) with the command git clone <url>. Clicking the “Code” button in the top-right corner opens a menu from which the https address can be copied:

With that, we can create the git command and clone the data:
> cd ~/IntSciCom/Helsinki/
> git clone https://version.helsinki.fi/aloytyno/helsinkiweather.gitThis creates directory helsinkiweather and, inside that, directory HelsinkiMalmi that contains four data files.
> ls helsinkiweather/HelsinkiMalmi/Malmi_2024.tsv Malmi_A.tsv Malmi_B.tsv Malmi_C.tsvThe same data files can be seen through the web interface.
Data packing and compression
When sharing files by email or removable media, it helps to pack multiple files to one and compress the data into a smaller place. On Windows, that is often done with the Zip program. On Linux, that is called zip for creating zipped files and unzip for opening zipped files. The format of the command is zip <output.zip> <list_of_files>. We can test that with the commands:
> cd helsinkiweather/
> zip malmi.zip HelsinkiMalmi/* adding: HelsinkiMalmi/Malmi_2024.tsv (deflated 90%)
adding: HelsinkiMalmi/Malmi_A.tsv (deflated 90%)
adding: HelsinkiMalmi/Malmi_B.tsv (deflated 90%)
adding: HelsinkiMalmi/Malmi_C.tsv (deflated 90%)One can check the contents of a zip file with unzip -l <file.zip>:
> unzip -l malmi.zip Archive: malmi.zip
Length Date Time Name
--------- ---------- ----- ----
32430 03-18-2024 11:44 HelsinkiMalmi/Malmi_2024.tsv
32308 03-18-2024 10:40 HelsinkiMalmi/Malmi_A.tsv
31948 03-18-2024 10:40 HelsinkiMalmi/Malmi_B.tsv
32171 03-18-2024 10:40 HelsinkiMalmi/Malmi_C.tsv
--------- -------
128857 4 filesWe can now delete the original data and recover the files from the zip-file with the command unzip <file.zip>:
> rm -r HelsinkiMalmi/
> unzip malmi.zip Archive: malmi.zip
inflating: HelsinkiMalmi/Malmi_2024.tsv
inflating: HelsinkiMalmi/Malmi_A.tsv
inflating: HelsinkiMalmi/Malmi_B.tsv
inflating: HelsinkiMalmi/Malmi_C.tsv > ls HelsinkiMalmi/Malmi_2024.tsv Malmi_A.tsv Malmi_B.tsv Malmi_C.tsvAbove, we used HelsinkiMalmi/* to select the files to zipped. Alternatively we can add argument -r (for ‘recursively’) and include all files within the directory. Thus, these two commands have the same behaviour:
> zip malmi.zip HelsinkiMalmi/*
> zip -r malmi.zip HelsinkiMalmi/Linux has its own zip-like programs called gzip and gunzip but, unlike zip, these can only be applied to single files. One often sees very largely files compressed with gzip, the suffix .gz (e.g. genome.fa.gz) revealing the format. We can test it with a smaller file:
> ls -l HelsinkiMalmi/Malmi_2024.tsv-rw-rw---- 1 username pepr_username 32430 Mar 18 11:44 HelsinkiMalmi/Malmi_2024.tsv> gzip HelsinkiMalmi/Malmi_2024.tsv
> ls -l HelsinkiMalmi/Malmi_2024.tsv.gz-rw-rw---- 1 username pepr_username 3375 Mar 18 11:44 HelsinkiMalmi/Malmi_2024.tsv.gzThe ls output reveals that the size of the file is decreased by ~90%, from 32430 bytes to 3375 bytes. Such reduction is typical for files with highly repetitive content (e.g. text files) whereas most graphics files are already compressed and cannot be further reduced with gzip. It is good to be aware that the command less can handle gzipped-files and one doesn’t need to uncompress the file just look inside it:
> less helsinkiweather/HelsinkiMalmi/Malmi_2024.tsv.gz | head -3Helsinki_Malmi_lentokenttä 1 1 00:00 -16.7
Helsinki_Malmi_lentokenttä 1 1 01:00 -16.6
Helsinki_Malmi_lentokenttä 1 1 02:00 -16.7The same is true e.g.for zcat and zgrep, equivalent of cat and grep for gzipped files:
> zgrep 12:00 HelsinkiMalmi/Malmi_2024.tsv.gz | head -3Helsinki_Malmi_lentokenttä 1 1 12:00 -16.9
Helsinki_Malmi_lentokenttä 1 2 12:00 -17.3
Helsinki_Malmi_lentokenttä 1 3 12:00 -17.2Above, gzip automatically added the suffix to the file when compressing it; gunzip automatically removes the suffix when decompressing it:
> gunzip HelsinkiMalmi/Malmi_2024.tsv.gz
> ls -l HelsinkiMalmi/Malmi_2024.tsv -rw-rw---- 1 username pepr_username 32430 Mar 18 11:44 HelsinkiMalmi/Malmi_2024.tsvtar archive files
Linux has another program, called tar, for packing files together. The name tar comes from tape archive and reveals that the program is pretty old; as such, it belongs to the core of Linux command-line skills.
tar can bundle multiple files into one archive file, recording the original directory structure. By default, it is recursive and the following command bundles together the files in the directory HelsinkiMalmi and creates the output file malmi.tar.
> tar --create --verbose --file malmi.tar HelsinkiMalmi/HelsinkiMalmi/
HelsinkiMalmi/Malmi_A.tsv
HelsinkiMalmi/Malmi_2024.tsv
HelsinkiMalmi/Malmi_C.tsv
HelsinkiMalmi/Malmi_B.tsvThis file is not compressed:
> ls -l malmi.tar -rw-rw---- 1 username pepr_username 143360 Mar 18 14:17 malmi.tarbut it can be compressed with gzip, reducing the size by more than 90% (from 143360 to 13309):
> gzip malmi.tar
> ls -l malmi.tar.gz -rw-rw---- 1 username pepr_username 13309 Mar 18 14:17 malmi.tar.gzThe original command looks clumsy and there are shortcuts to make it shorter; moreover, the suffix .tgz is often used in place of .tar.gz. The file bundling and compression (that were done separately above) can be obtained with a single command and, instead of the long command format tar --create --gzip --file, simple tar czf is typically used. The long and short versions of the command are:
> tar --create --gzip --file malmi.tar.gz HelsinkiMalmi/
> tar czf malmi.tgz HelsinkiMalmi/
> ls -l malmi.t*-rw-rw---- 1 usename pepr_usename 13299 Mar 18 14:17 malmi.tar.gz
-rw-rw---- 1 usename pepr_usename 13299 Mar 18 14:52 malmi.tgzThe contents of a tgz-file can be listed with tar tzf <file.tgz>:
> tar tzf malmi.tgz HelsinkiMalmi/
HelsinkiMalmi/Malmi_A.tsv
HelsinkiMalmi/Malmi_2024.tsv
HelsinkiMalmi/Malmi_C.tsv
HelsinkiMalmi/Malmi_B.tsvThe tgz-file doesn’t need to be unpacked in its entirety and, knowing the contents, one can extract single files by specifying its file path:
> rm -r HelsinkiMalmi/
> tar xzf malmi.tgz HelsinkiMalmi/Malmi_2024.tsv
> ls HelsinkiMalmi/Malmi_2024.tsvThe same wildcards can be used in the specification of the files to be extracted (here’ v stands for --verbose and gives information about the process):
> tar xvzf malmi.tgz HelsinkiMalmi/Malmi_?.tsvHelsinkiMalmi/Malmi_A.tsv
HelsinkiMalmi/Malmi_C.tsv
HelsinkiMalmi/Malmi_B.tsvThe whole tgz-file is unpacked if no additional parameters are given:
> tar xzf malmi.tgzThere are multiple different compression algorithms. After gzip, the most commonly used is bzip2. It works like gzip but the suffix is .bz2:
> bzip2 HelsinkiMalmi/Malmi_2024.tsv
> ls -lt HelsinkiMalmi/Malmi_2024.tsv.bz2 -rw-rw---- 1 username pepr_username 2202 Mar 18 11:44 HelsinkiMalmi/Malmi_2024.tsv.bz2> bunzip2 HelsinkiMalmi/Malmi_2024.tsv.bz2 In tar, the bzip2-compression is selected with the argument -j and the suffix is .tar.bz2 or .tbz:
> tar cjf malmi.tbz HelsinkiMalmi/
> tar tjf malmi.tbzHelsinkiMalmi/
HelsinkiMalmi/Malmi_A.tsv
HelsinkiMalmi/Malmi_2024.tsv
HelsinkiMalmi/Malmi_C.tsv
HelsinkiMalmi/Malmi_B.tsv> tar xjf malmi.tbzFor maximal reproducibility and automation, online data should retrieved using command-line tools. Many sites provide an REST interface that allows limiting the data retrieval to subsections of the full data. Increasingly the data are provided in JSON format and efficient command-line tools exist for their conversion. Compression can reduce the file sizes by more than 90%. Large files should be always compressed; uncompressed files waste resources and the scarce money needed for something better. Many programs can read compressed files or the files can be decompressed on the fly. Linux supports zip files familiar from Windows but the most widely-used compression and packing methods on Linux and gzip and tar.